Slurm which stands for (Simple Linux Utility For Resource Management) is a great, powerful, modular, and open-source workload manager and job scheduler built for Linux, Clusters, and Supercomputers.
Slurm is a fault-tolerant and highly pluggable cluster management and job scheduling system with many optional plugins that you can use. It provides workload management on several powerful computers and data centers around the world.
The Main Functions of Slurm
Slurm has three major functions, first of all, it allocates exclusive and/or non-exclusive access to resources to users who want to do some work for a given period of time.
Next, Slurm avails a framework that helps to start, execute, and monitor work on a set of allocated hosts in a cluster and its final function is that it controls resource usage by managing a queue of pending work.
Slurm Features
You can find a lot of workload managers out there but Slurm has many unique features that differentiate it from other workload managers and these features include:
- FOSS – free and open source.
- Scalability – designed to work in a heterogeneous cluster with tens of millions of CPUs.
- Performance – high performance where it can accept up to 1000 jobs per second.
- Portable – it can work on several systems although originally designed for Linux.
- Fault Tolerant – it is highly tolerant to system failures.
- Flexible – highly pluggable with plugin mechanisms to support diverse interconnections, schedulers, authentication mechanisms plus many more.
- Power Management – jobs being executed can specify their required CPU frequency and the power used by jobs is recorded also jobs not in execution can powered down until required.
- Resizable Jobs – jobs can grow and shrink as demanded.
- Status Jobs – status running jobs at the level of individual tasks necessary to identify load imbalances and many other system problems.
Slurm Architecture
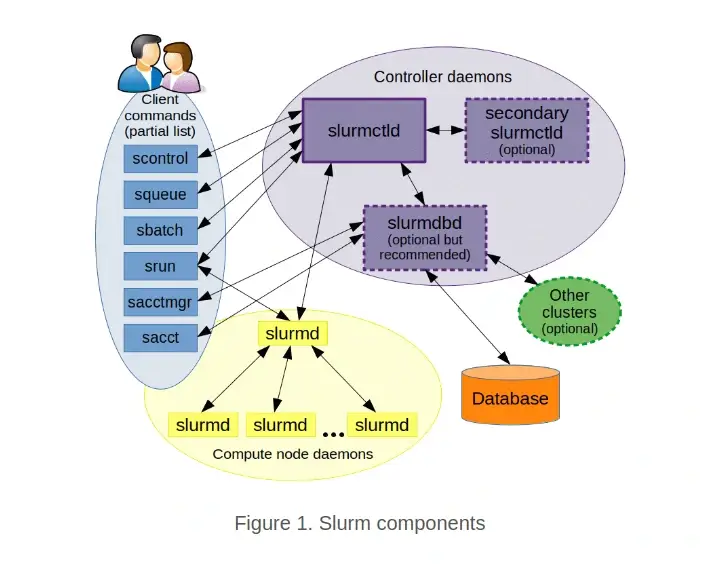
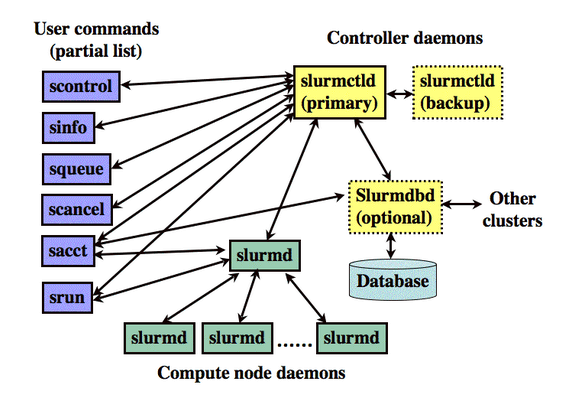
The Slurm system is based on a centralized manager, slurmctld which monitors different resources and work, and it may include a backup manager responsible for protecting the system state in case of any failure.
Each host on the cluster has a slurmd daemon which is compared to a remote shell and receives work, executes it, returns status, and then waits for more work to execute, the daemon also enables fault-tolerant communication in the system setup hierarchy.
There is also an optional slurmdbd (slurm database daemon) used to record accounting information from several Slurm-managed clusters in a single database. You can read about the complete architecture from here.
Below is an image showing the different components of the Slurm system:
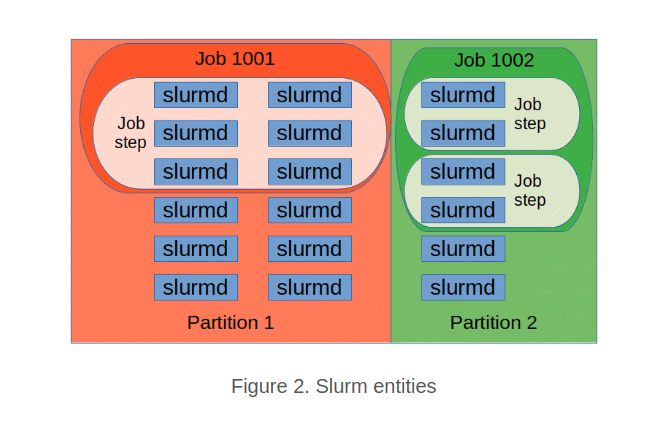
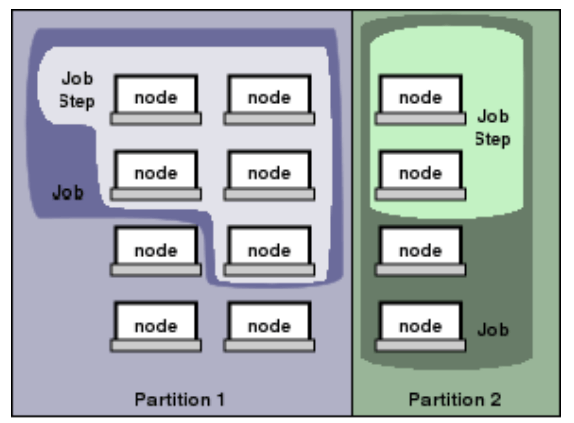
An image showing different Slurm system entities:
Slurm has also been packaged for Debian and Ubuntu (named slurm-wlm), Fedora, and NetBSD (in pkgsrc), and FreeBSD.
$ sudo apt search slurm-wlm
You may want to check and try out the Slurm cluster management and job scheduling system if you are working with Linux clusters of any size. For any additional information you can leave your thoughts about Slurm here by dropping a comment in the comment section below.